Iterated Second-Order Label Sensitive Pooling for 3D Human Pose Estimation
C. Ionescu, J. Carreira and C. Sminchisescu (CVPR 2014)
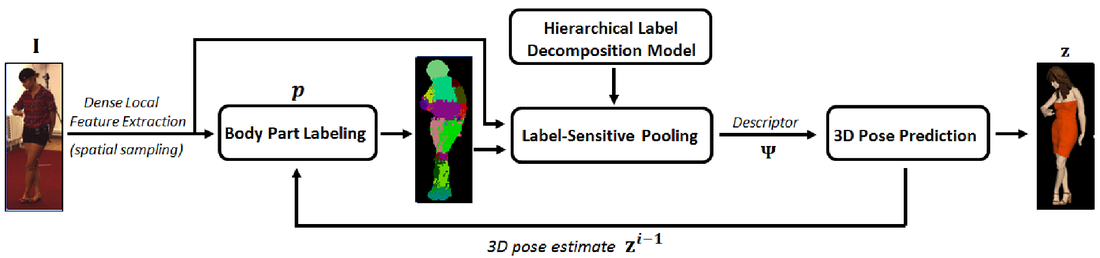
Overview of the information flow of the different estimates in our proposed model.
Description
Recently, the emergence of Kinect systems has demonstrated the benefits of predicting an intermediate body part labeling for 3D human pose estimation, in conjunction with RGB-D imagery. The availability of depth information plays a critical role, so an important question is whether a similar representation can be developed with sufficient robustness in order to estimate 3D pose from RGB images. This paper provides evidence for a positive answer, by leveraging (a) 2D human body part labeling in images, (b) second-order label-sensitive pooling over dynamically computed regions resulting from a hierarchical decomposition of the body, and (c) iterative structured-output modeling to contextualize the process based on 3D pose estimates. For robustness and generalization, we take advantage of a recent large-scale 3D human motion capture dataset, Human3.6M[18] that also has human body part labeling annotations available with images. We provide extensive experimental studies where alternative intermediate representations are compared and report a substantial 33% error reduction over competitive discriminative baselines that regress 3D human pose against global HOG features.
The article can be downloaded from here. The CVPR 2014 talk (with slides) can be seen here.
Recently, the emergence of Kinect systems has demonstrated the benefits of predicting an intermediate body part labeling for 3D human pose estimation, in conjunction with RGB-D imagery. The availability of depth information plays a critical role, so an important question is whether a similar representation can be developed with sufficient robustness in order to estimate 3D pose from RGB images. This paper provides evidence for a positive answer, by leveraging (a) 2D human body part labeling in images, (b) second-order label-sensitive pooling over dynamically computed regions resulting from a hierarchical decomposition of the body, and (c) iterative structured-output modeling to contextualize the process based on 3D pose estimates. For robustness and generalization, we take advantage of a recent large-scale 3D human motion capture dataset, Human3.6M[18] that also has human body part labeling annotations available with images. We provide extensive experimental studies where alternative intermediate representations are compared and report a substantial 33% error reduction over competitive discriminative baselines that regress 3D human pose against global HOG features.
The article can be downloaded from here. The CVPR 2014 talk (with slides) can be seen here.
Code and Results
Matlab code is available to reproduce the results in the article. Just unpack the archive and check the instructions inside. The code is self-contained but data needs to be downloaded from the Human3.6M dataset. Feel free to contact us with questions, suggestions and/or bug reports.
Comparative results on a select set of images are shown in the video below.
Matlab code is available to reproduce the results in the article. Just unpack the archive and check the instructions inside. The code is self-contained but data needs to be downloaded from the Human3.6M dataset. Feel free to contact us with questions, suggestions and/or bug reports.
Comparative results on a select set of images are shown in the video below.
|
|
Acknowledgements
This work was supported in part by CNCS-UEFISCDI under CT-ERC-2012-1 and PCE-2011-3-0438. Research was performed in part while Joao Carreira was at ISR-Coimbra, supported by FCT under PTDC/EEA-CRO/122812/2010 and SFRH/BPD/84194/2012. The authors are grateful to Elisabeta Marinoiu for her generous help with the 3D human modeling and the visualizations used in the paper
This work was supported in part by CNCS-UEFISCDI under CT-ERC-2012-1 and PCE-2011-3-0438. Research was performed in part while Joao Carreira was at ISR-Coimbra, supported by FCT under PTDC/EEA-CRO/122812/2010 and SFRH/BPD/84194/2012. The authors are grateful to Elisabeta Marinoiu for her generous help with the 3D human modeling and the visualizations used in the paper
